This is the main function of the package.
This function clusters hot spots into fires. It can be used to
reconstruct fire history and detect fire ignition points.
Usage
hotspot_cluster(
hotspots,
lon = "lon",
lat = "lat",
obsTime = "obsTime",
activeTime = 24,
adjDist = 3000,
minPts = 4,
minTime = 3,
ignitionCenter = "mean",
timeUnit = "n",
timeStep = 1
)Arguments
- hotspots
List/Data frame. A list or a data frame which contains information of hot spots.
- lon
Character. The name of the column of the list which contains numeric longitude values.
- lat
Character. The name of the column of the list which contains numeric latitude values.
- obsTime
Character. The name of the column of the list which contains the observed time of hot spots. The observed time has to be in date, datetime or numeric.
- activeTime
Numeric (>=0). Time tolerance. Unit is time index.
- adjDist
Numeric (>0). Distance tolerance. Unit is metre.
- minPts
Numeric (>0). Minimum number of hot spots in a cluster.
- minTime
Numeric (>=0). Minimum length of time of a cluster. Unit is time index.
- ignitionCenter
Character. Method to calculate ignition points, either "mean" or "median".
- timeUnit
Character. One of "s" (seconds), "m" (minutes), "h" (hours), "d" (days) and "n" (numeric).
- timeStep
Numeric (>0). Number of units of
timeUnitin a time step.
Value
A spotoroo object. The clustering results. It is also a list:
hotspots: A data frame contains information of hot spots.lon: Longitude.lat: Latitude.obsTime: Observed time.timeID: Time index.membership: Membership label.noise: Whether it is a noise point.distToIgnition: Distance to the ignition location.distToIgnitionUnit: Unit of distance to the ignition location.timeFromIgnition: Time from ignition.timeFromIgnitionUnit: Unit of time from ignition.
ignition: A data frame contains information of ignition points.lon: Longitude.lat: Latitude.obsTime: Observed time.timeID: Time index.obsInCluster: Number of observations in the cluster.clusterTimeLen: Length of time of the cluster.clusterTimeLenUnit: Unit of length of time of the cluster.
setting: A list contains the clustering settings.
Details
Arguments timeUnit and timeStep need to be
specified to convert date/datetime/numeric to time index.
More details can be found in transform_time_id().
This clustering algorithm consisted of 5 steps:
In step 1, it defines \(T\) intervals using the time index
$$Interval(t) = [max(1, t - activeTime),t]$$
where \(t = 1, 2, ..., T\), and \(T\) is the maximum time index.
activeTime is an argument that needs to be specified. It represents
the maximum time difference between two hot spots in the same local
cluster. Please notice that a local cluster is different with a cluster
in the final result. More details will be given in the next part.
In step 2, the algorithm performs spatial clustering on each interval.
A local cluster is a cluster found in an interval. Argument adjDist
is used to control the spatial clustering. If the distance between two
hot spots is smaller or equal to adjDist, they are directly-connected. If
hot spot A is directly-connected with hot spot B and hot spot B is
directly-connected with hot spot C, hot spot A, B and C are
connected. All connected hot spots become a local cluster.
In step 3, the algorithm starts from interval \(1\). It marks all
hot spots in this interval and records their membership labels.
Then it moves on to interval \(2\). Due to a hot spot could exist in
multiple intervals, it checks whether any hot spot in interval \(2\)
has been marked. If there is any, their membership labels will be
carried over from the record. Unmarked hot spots in interval \(2\),
which share the same local cluster with marked hot spots, their
membership labels are carried over from marked hot spots. If a unmarked
hot spot shares the same local cluster with multiple marked hot spots, the
algorithm will carry over the membership label from the nearest one. All
other unmarked hot spots in interval \(2\) that do not share the same
cluster with any marked hot spot, their membership labels will be adjusted
such that the clusters they belong to are considered to be new clusters.
Finally, all
hot spots in interval \(2\) are marked and their membership labels are
recorded. This process continues for interval \(3\), \(4\), ...,
\(T\). After finishing step 3, all hot spots are marked and their
membership labels are recorded.
In step 4, it checks each cluster. If there is any cluster contains less
than minPts hot spots, or lasts shorter than minTime, it will not be
considered to be a cluster any more, and their hot spots will be
assigned with -1 as their membership labels. A hot spot with membership
label -1 is noise.
Arguments minPts and minTime need to be specified.
In step 5, the algorithm finds the earliest observed hot spots in each
cluster and records them as ignition points. If there are multiple
earliest observed hot spots in a cluster, the mean or median of the
longitude values and the latitude values will be used as the coordinate
of the ignition point. This needs to be specified in argument
ignitionCenter.
Examples
# \donttest{
# Time consuming functions (>5 seconds)
# Get clustering results
result <- hotspot_cluster(hotspots,
lon = "lon",
lat = "lat",
obsTime = "obsTime",
activeTime = 24,
adjDist = 3000,
minPts = 4,
minTime = 3,
ignitionCenter = "mean",
timeUnit = "h",
timeStep = 1)
#>
#> ──────────────────────────────── SPOTOROO 0.1.6 ────────────────────────────────
#>
#> ── Calling Core Function : `hotspot_cluster()` ──
#>
#> ── "1" time index = 1 hour
#> ✔ Transform observed time → time indexes
#> ℹ 970 time indexes found
#>
#> ── activeTime = 24 time indexes | adjDist = 3000 meters
#> ✔ Cluster
#> ℹ 16 clusters found (including noise)
#>
#> ── minPts = 4 hot spots | minTime = 3 time indexes
#> ✔ Handle noise
#> ℹ 6 clusters left
#> ℹ noise proportion : 0.935 %
#>
#> ── ignitionCenter = "mean"
#> ✔ Compute ignition points for clusters
#> ℹ average hot spots : 176.7
#> ℹ average duration : 131.9 hours
#>
#> ── Time taken = 0 mins 1 sec for 1070 hot spots
#> ℹ 0.001 secs per hot spot
#>
#> ────────────────────────────────────────────────────────────────────────────────
# Make a summary of the clustering results
summary(result)
#>
#> ──────────────────────────────── SPOTOROO 0.1.4 ────────────────────────────────
#>
#> ── Calling Core Function : `summary_spotoroo()` ──
#>
#> CLUSTERS: ALL
#> OBSERVATIONS: 1070
#> FROM: 2019-12-29 13:10:00
#> TO: 2020-02-07 22:50:00
#>
#>
#> ── Clusters
#> ℹ Number of clusters: 6
#>
#> Observations in cluster
#> Min. 1st Qu. Mean 3rd Qu. Max.
#> 111.0 131.0 176.7 233.2 256.0
#> Duration of cluster (hours)
#> Min. 1st Qu. Mean 3rd Qu. Max.
#> 111.2 118.2 131.9 146.1 148.3
#>
#> ── Hot spots (excluding noise)
#> ℹ Number of hot spots: 1060
#>
#> Distance to ignition points (m)
#> Min. 1st Qu. Mean 3rd Qu. Max.
#> 0.0 2840.3 5058.2 6981.6 13452.7
#> Time from ignition (hours)
#> Min. 1st Qu. Mean 3rd Qu. Max.
#> 0.0 25.2 62.5 98.2 148.3
#>
#> ── Noise
#> ℹ Number of noise points: 10 (0.93 %)
#>
#>
#> ────────────────────────────────────────────────────────────────────────────────
# Make a plot of the clustering results
plot(result, bg = plot_vic_map())
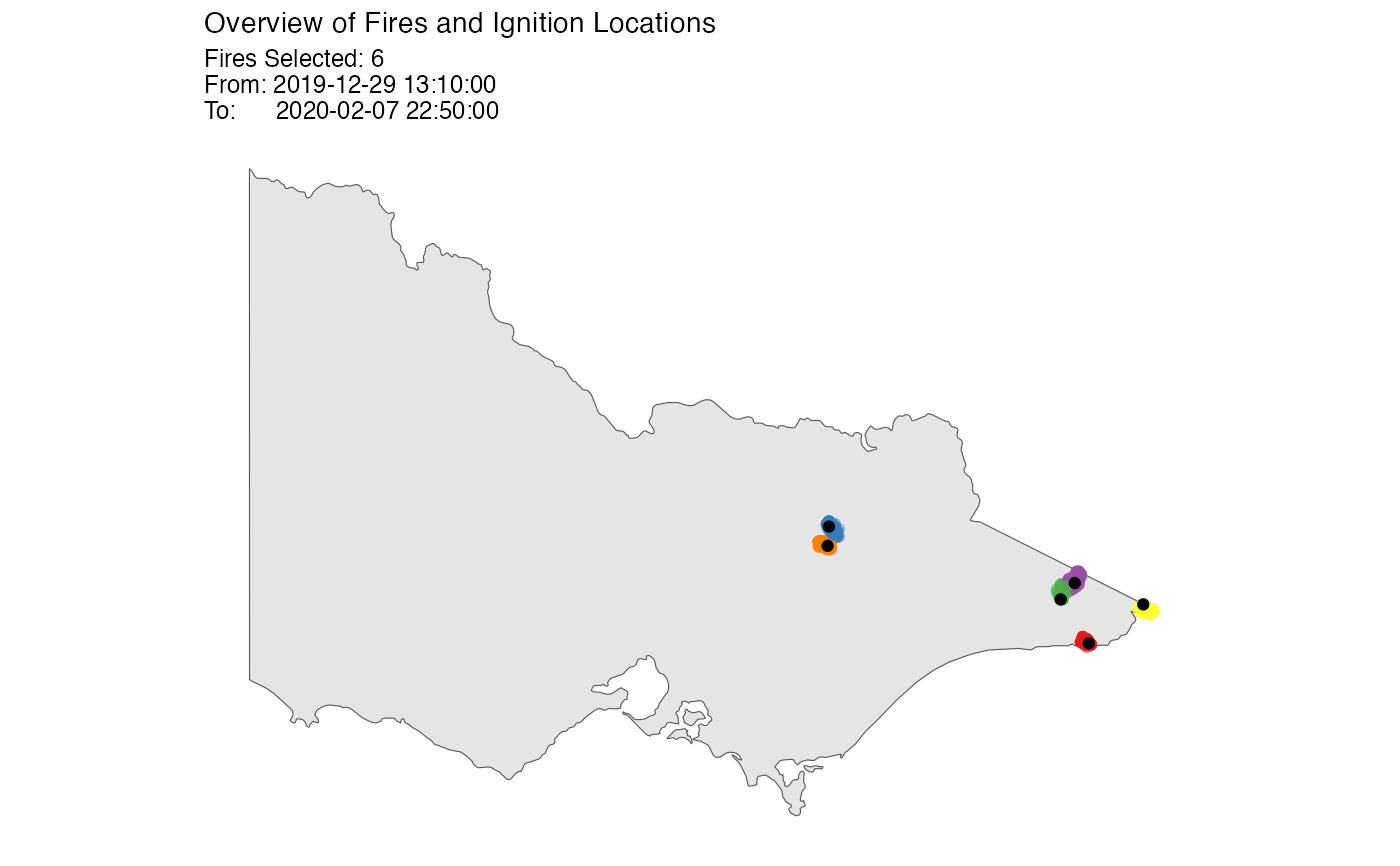 # }
# }